在当今信息爆炸的时代,处理和理解海量文本数据的需求日益增长。自然语言处理(NLP)领域的研究者们一直在探索如何构建更高效、更强大且更灵活的语言模型来应对这一挑战。然而,现有的大型语言模型,尤其是基于Transformer架构的模型,虽然在多个任务上取得了显著的成就,但它们在处理长文本时仍面临着内存和计算资源的巨大需求。这些需求限制了模型在资源受限的环境中的应用,并可能导致推理速度变慢,影响用户体验。
为了解决这些问题,一种新型的混合Transformer-Mamba语言模型——Jamba应运而生。Jamba模型通过结合Transformer的注意力机制和Mamba的状态空间建模能力,实现了对长文本更有效的处理,降低了内存占用,并提高了推理速度和模型的吞吐量。这一突破性进展不仅为NLP领域带来了新的技术革新,也为构建更加高效和实用的语言模型铺平了道路。
模型架构
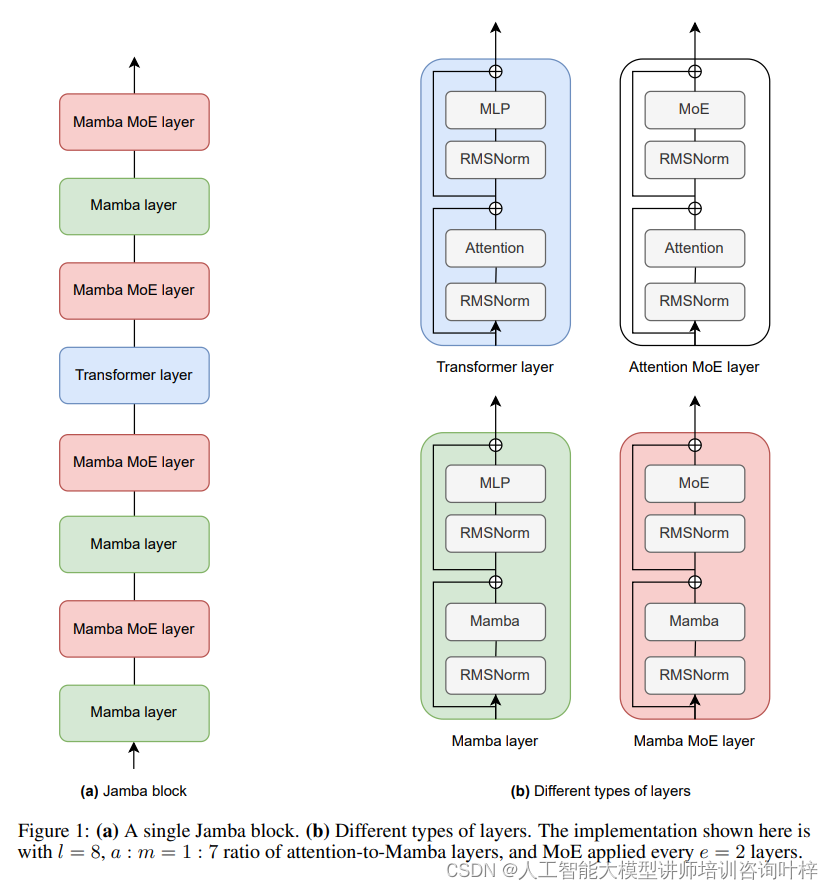
Figure 1展示了Jamba模型的基本构成单元和不同类型的层。Jamba模型的结构组成如下:
(a) 单一Jamba块
一个Jamba块是构成Jamba模型的基本单元。在这个块中,包含了多层的网络结构,这些层可以是Transformer层,也可以是Mamba层,或者是混合了专家(MoE)的层。这些层按照特定的比例和顺序排列,以实现模型的最佳性能。
(b) 不同类型的层
Jamba模型中包含几种不同类型的层:
-
Transformer层:这是传统Transformer模型中使用的层,主要负责处理输入数据的自注意力(Self-Attention)机制,允许模型在生成输出时考虑到序列中的所有位置。
-
Mamba层:Mamba层是一种状态空间模型(State-Space Model, SSM),相比于Transformer层,它在处理长序列数据时更为高效,并且能够更好地捕捉长距离依赖关系。
-
MoE层:即混合专家层,是一种引入模型稀疏性的技术,通过多个“专家”网络来处理不同的输入部分,然后通过一个门控机制(Gating Mechanism)来选择最合适的专家输出,从而提高模型的容量和灵活性。
Jamba块具有以下特征:
- l = 8:表示每个Jamba块包含8层。
- a : m = 1 : 7:表示在这8层中,有1层是Transformer的注意力层,而有7层是Mamba层。这个比例旨在平衡模型的计算效率和对长距离依赖的处理能力。
- MoE应用频率 e = 2:表示每2层就会有一个MoE层,这意味着在8层的Jamba块中,有4个MoE层被应用。这样的设置允许模型在保持参数数量可控的同时,增加模型的容量和灵活性。
这种结构设计使得Jamba模型能够结合Transformer和Mamba层的优势,同时通过MoE层提高模型的扩展性和适应性。通过这种方式,Jamba能够在保持较小的内存占用和高效的计算性能的同时,实现对长上下文的理解和处理。
Jamba模型的核心创新在于其混合架构,该架构巧妙地融合了Transformer和Mamba两种不同的神经网络层。Transformer层以其高效的注意力机制而闻名,而Mamba层则是一种新型的状态空间模型,擅长捕捉序列数据中的长距离依赖关系。通过这种混合设计,Jamba能够同时利用两种模型的优势,实现对长文本的高效处理。
在Jamba模型中,Transformer层和Mamba层以特定的比例交替出现。这种设计允许模型在保持Transformer层强大的并行处理能力的同时,通过Mamba层引入对长距离依赖的敏感性。这种协同作用不仅提高了模型对上下文的理解能力,还显著降低了处理长序列时所需的内存和计算资源。
为了进一步提升模型的容量和灵活性,Jamba模型引入了混合专家(MoE)技术。MoE允许模型在不同的专家网络中分配计算任务,每个专家可以专注于解决特定类型的问题。这种设计不仅增加了模型的总参数数量,而且通过智能路由机制,确保了在每次前向传播中只激活一部分参数,从而有效控制了计算成本。
Jamba模型的另一个显著特点是其高度的可配置性。模型的设计者可以根据不同的硬件资源和性能要求,调整模型中的参数,如层数、注意力与Mamba层的比例、MoE的使用频率等。这种灵活性使得Jamba能够适应各种不同的应用场景,从资源受限的移动设备到高性能的服务器环境。
在Jamba模型的设计中,特别关注了内存使用和吞吐量的优化。通过减少关键值(KV)缓存的大小,Jamba显著降低了模型的内存占用。同时,通过优化Mamba层的计算效率,Jamba在处理长序列时展现出了更高的吞吐量,这对于需要快速响应的实时应用场景尤为重要。
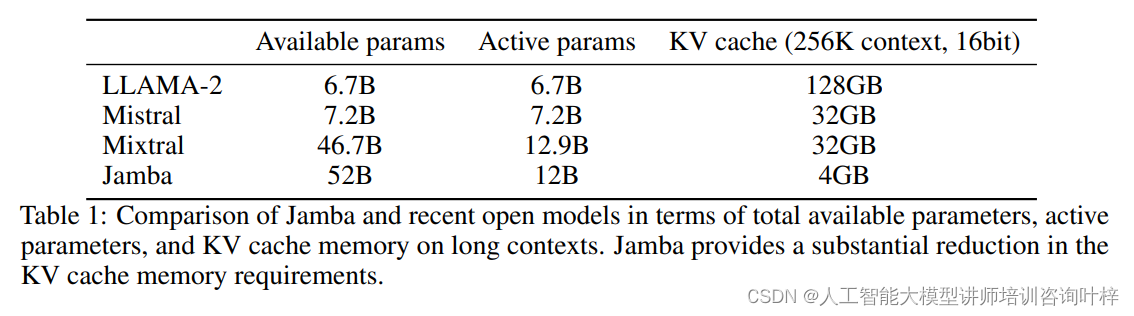
高效部署实现与性能优化
Jamba模型特别针对单个80GB GPU进行了优化配置,以实现在保证质量和吞吐量的同时,最大程度地适应硬件限制。具体来说,Jamba由4个Jamba块组成,每个块包含8层,其中包括1:7的注意力层到Mamba层的比例,以及每两层使用一次MoE(专家混合)代替单个MLP(多层感知器)。这种配置不仅使得模型能够适应单个80GB GPU的内存限制,同时还保持了高效的计算性能。

Jamba模型在处理长序列数据时展现出了卓越的吞吐量。在不同的批处理大小和上下文长度设置下,Jamba的吞吐量表现均优于现有的Mixtral-8x7B和Llama-2 70B模型。特别是在长上下文处理方面,Jamba的吞吐量是Mixtral的三倍,这一优势在处理超过128K个token的上下文时尤为明显。
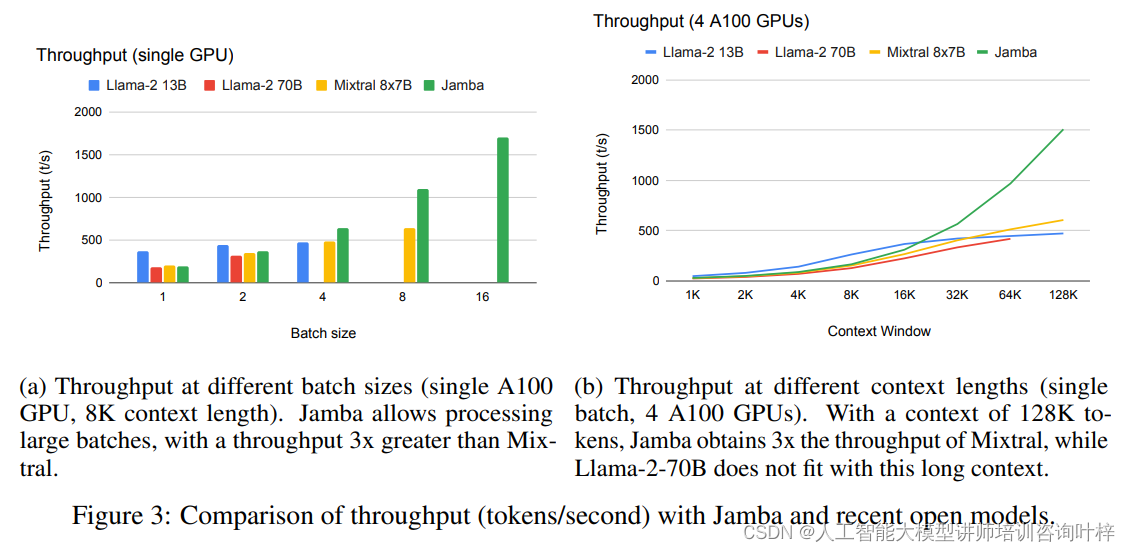
Jamba模型的训练采用了NVIDIA H100 GPU,并使用了一种专有的内部框架,该框架支持大规模训练,包括FSDP、张量并行、序列并行和专家并行等技术。Jamba的训练数据集包含了来自网络、书籍和代码的文本数据,这些数据经过了质量筛选和去重处理。
Jamba模型的训练得益于NVIDIA H100 GPU的强大计算能力,以及开发团队自研的高效训练框架,该框架集成了全参数数据并行、张量并行、序列并行和专家并行等先进技术,确保了大规模训练的效率。模型所依赖的内部数据集涵盖了来自网络、书籍和代码的文本数据,且数据集经过了最新的更新和严格的质量筛选与去重处理,以保证训练数据的质量和多样性。这些因素共同为Jamba模型的优异性能打下了坚实的基础。
评估
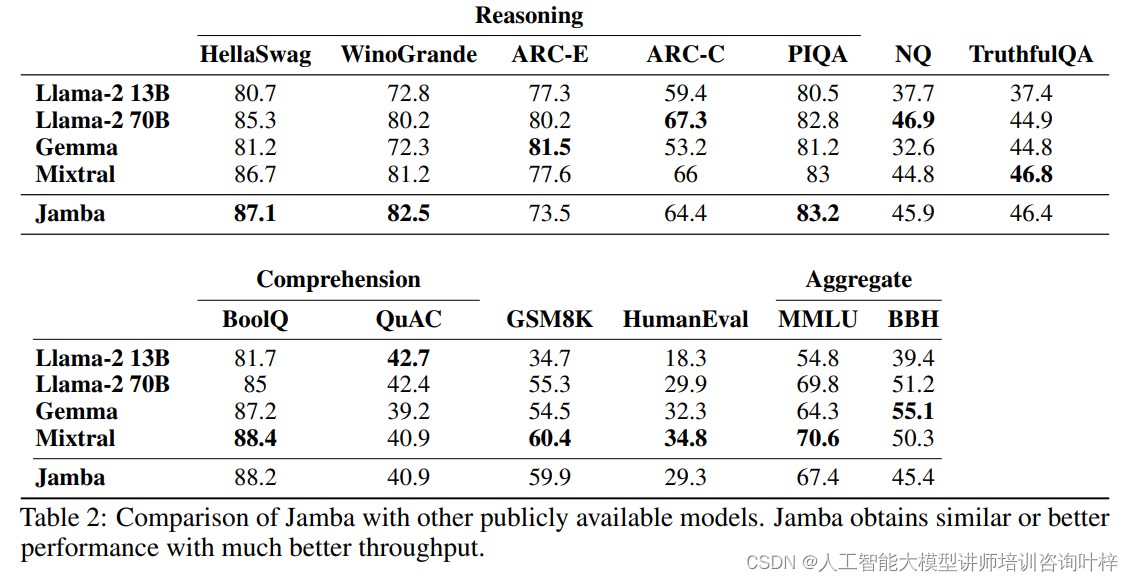
Jamba在多个标准的学术基准测试上进行了评估,这些测试覆盖了常识推理、阅读理解、语言理解等多个方面。例如,在HellaSwag、WinoGrande、ARC等测试中,Jamba展现了出色的推理能力;在BoolQ、QuAC等阅读理解测试中,模型的理解和回答问题的能力得到了验证。Jamba还在MMLU和BBH等综合基准测试中表现优异,这些测试综合考察了模型在多个任务上的语言理解能力。
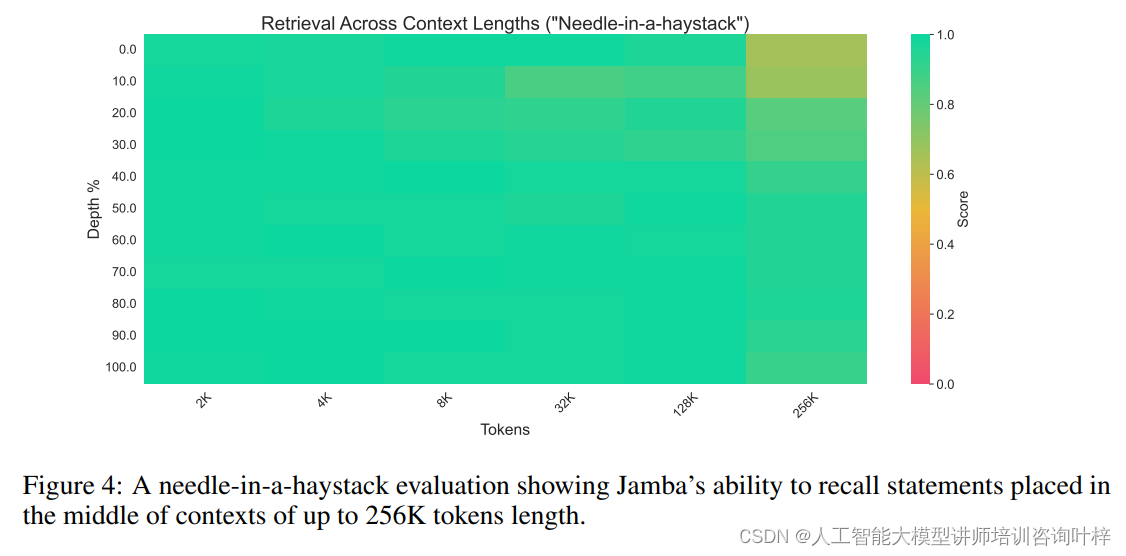
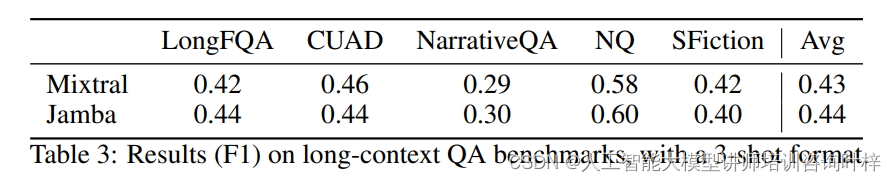
除了标准的学术基准测试,Jamba在处理长上下文数据方面的能力也经过了严格的评估。通过"针堆中找针"的测试,Jamba证明了其在长文本中检索信息的能力。此外,Jamba还在L-Eval中的长上下文问答数据集上进行了评估,这些数据集包括NarrativeQA、LongFQA、Natural Questions等,Jamba在这些测试中的表现进一步证实了其在处理长文本方面的卓越性能。
在与其他公开可用的模型进行对比时,Jamba显示出了其在相似参数规模下的性能优势。与Llama-2、Mixtral等模型相比,Jamba在保持较小的总参数量的同时,实现了更高的活跃参数使用效率和更好的吞吐量,同时在多个基准测试中取得了相似或更好的成绩。
Jamba的高效率和低内存占用是其显著特点之一。在处理长达256K个token的上下文时,Jamba的内存占用仅为4GB,远低于其他同类模型。这一优势使得Jamba即使在资源受限的环境中也能高效运行。
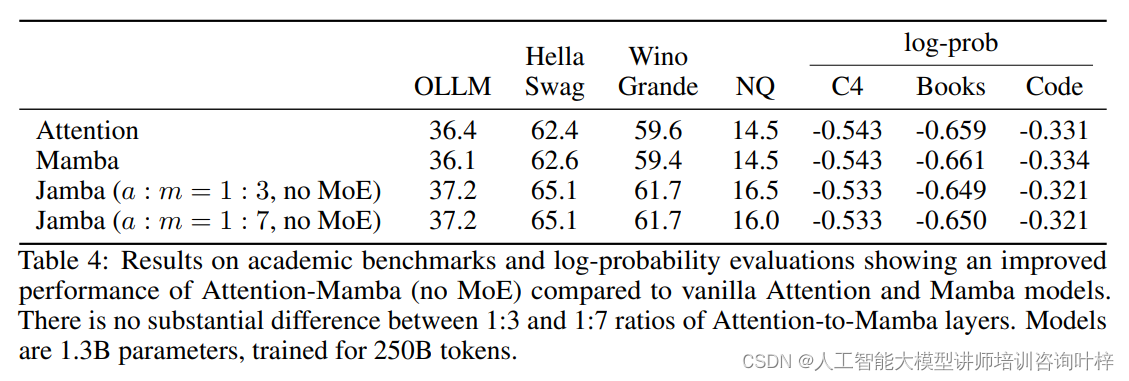
在消融实验中,研究者首先探讨了Transformer注意力层和Mamba层的结合比例对模型性能的影响。实验结果表明,混合模型在1:3和1:7的注意力到Mamba层的比例下表现相似,但1:7的比例在计算效率上更胜一筹。因此,这一比例被选为后续实验的配置。
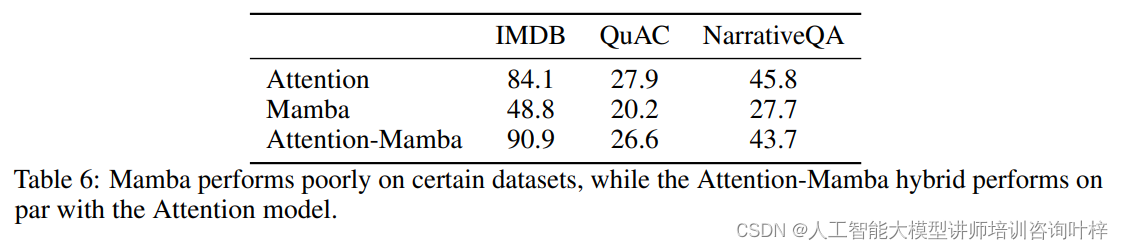
进一步的实验分析了纯Mamba模型在某些任务上表现不佳的原因,尤其是在需要上下文学习能力的任务中。相比之下,混合模型能够成功执行上下文学习,即使只有少数几层是注意力层。这表明注意力机制可能有助于模型更好地学习上下文信息。
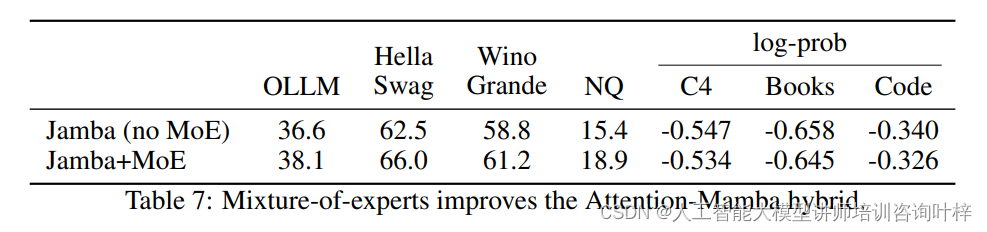
研究者还研究了MoE在大规模模型中与混合注意力-Mamba架构结合的效果。实验结果表明,MoE能够显著提升模型的性能,同时保持了计算的可行性。
在训练大规模模型时,遇到了Mamba层内部激活值过大导致损失激增的问题。为了解决这个问题,研究者引入了RMSNorm来稳定训练过程,有效地防止了损失的剧烈波动。
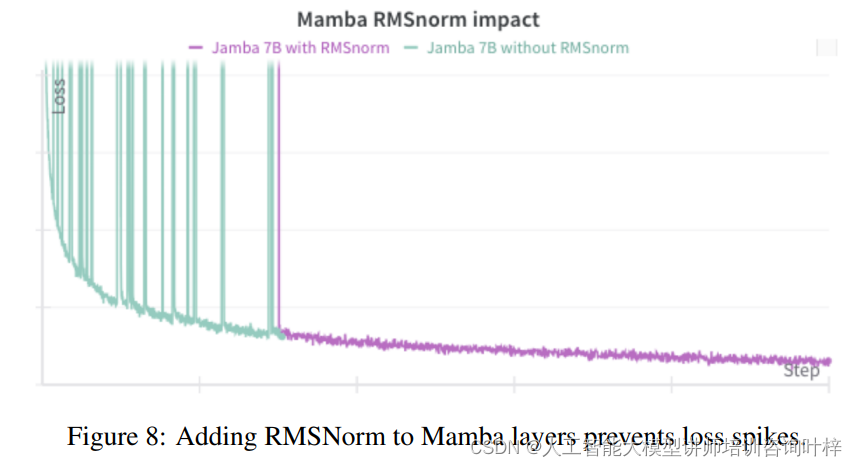
研究者还探讨了Jamba模型是否需要显式的位置信息。实验结果表明,即使没有显式的位置编码,Jamba模型也能取得良好的性能,这表明Mamba层可能已经提供了足够的位置信息。

这些实验结果和开发过程中的洞见将为未来混合注意力-状态空间模型的研究提供指导。为了推动这一领域的研究,研究者计划公开小规模训练的模型检查点。发布的最大型模型具备12亿活跃参数和52亿总参数,支持处理长达256K个token的上下文,并且能够在单个80GB GPU上处理140K-token的文本。Jamba模型的成功不仅表现在其卓越的性能上,还在于它为自然语言处理技术的未来研究和应用开辟了新的可能性。
论文链接:https://arxiv.org/abs/2403.19887
GitHub 地址:https://www.ai21.com/jamba





![[AI开发配环境]VSCode远程连接ssh服务器](https://img-blog.csdnimg.cn/direct/17c16560596747548046d3a4f0a14920.png)